Modeller med konfidens
Kunstig intelligens (KI) har i løbet af det seneste årti fundet anvendelse inden for et væld af forskellige sektorer, og det bruges i stigende grad som et værktøj til at optimere og automatisere industrielle processer og opgaver. Eksempler på anvendelser inkluderer kvalitetssikring mht. produktionsudsving, ”smart factory” og forudsigende vedligeholdelse, ”smart farming”, modeller til prognoser for epidemier, assisteret patologi, samt billedanalyse og biometri. Der er efterhånden ingen tvivl om at vi kan se ind i en fremtid, hvor KI og maskinlæring-baserede algoritmer vil blive en mere og mere integreret del af menneskets samfund og hverdag.
Det er dog vigtigt at huske, at en KI stadig blot består af algoritmer udført af en computer – algoritmer der (med få undtagelser) hverken kan lave risikovurderinger eller forstå evt. konsekvenser af dårlige valg. I nogle tilfælde kan forkerte beslutninger være katastrofale, som fx i 2016 da en passager i en selvkørende bil omkom, efter bilens autonome system fejlklassificerede en hvid trailer som værende en del af himlen (NHTSA, 2017). Eller i 2020 da en uskyldig mand blev beskyldt for en forbrydelse grundet en fejl begået af et ansigtsgenkendelsessystem (Hill, 2020). På www.incidentdatabase.ai/ findes oversigter over (sandsynligvis kun en meget lille del af) de uheld, der er forekommet grundet beslutninger taget af KI-systemer.
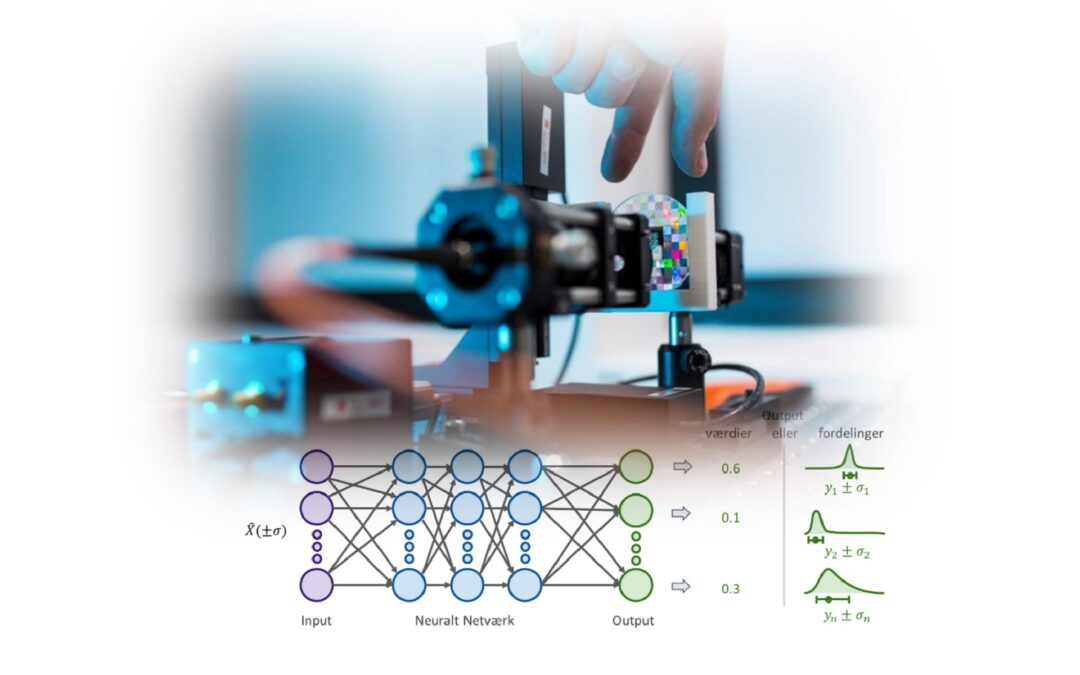
En helt fundamental fejl i rigtig mange KI-modeller er deres manglende evne til at svare: ”Tak fordi du spørger, men jeg ved det ikke”. Som mennesker har vi en helt naturlig evne (kognitiv sans) til at vide, hvornår vi er i tvivl om noget, og hvornår vi ved noget. KI-modeller har, desværre, ikke helt den samme sans for, hvornår de er sikre, og hvornår de er usikre, og til det helt centrale spørgsmål om, hvorvidt ”KI-modeller ved, hvad de ikke ved”, er svaret oftest nej. Dette er især tilfældet, når en model pludselig skal tage stilling til et nyt datasæt, hvor der ikke har været lignende fortilfælde. I stedet for at svare noget tilfældigt, ville det være passende, hvis modellen gav et svar, der så var behæftet med en meget stor usikkerhed.
Du kan læse hele rapporten her.